
Imagine being able to automate processes on websites like filling in form data, downloading files from pages, and many more. For programmers, being able to successfully perform these processes helps tremendously with larger ambitious projects. Luckily, a powerful technique called Web Scraping is available. Web Scraping allows you to automate large-scale data collection and data insertion by simulating the browser. One tool that can be effectively used to support this functionality is Puppeteer. Puppeteer is an API built off of Node.js that allows us to web scrape by providing users the power to control web pages in chromium browsers such as Google Chrome and Microsoft Edge. This makes Puppeteer a valuable tool to master for web scraping due to the diverse range of benefits that it provides. Imagine being able to automate processes on websites like filling in form data, downloading files from pages, and many more. For programmers, being able to successfully perform these processes helps tremendously with larger and ambitious projects. Web Scraping allows you to automate large-scale data collection and data insertion by simulating the browser.
More specifically, Puppeteer is a headless browser; unlike normal browsers which require human interaction, interaction with Puppeteer can be done using a machine, thus automating the process. This provides a simple and effective platform for web scraping, as it mimics human activity. Before going into the code, we need to first have a solid grasp on some core fundamentals:
- First and foremost, a good grasp of HTML is essential to scrape any website. Since scraping is essentially your computer’s interaction with HTML elements, understanding HTML beforehand will make your job easier.
- One problem you will likely run into is anti-bot measures taken by websites. Have you ever opened a website and been presented with an annoying captcha? Now you know exactly why they are in place: Websites don’t like excessive traffic from bots, so they take measures to block them. Captchas are simply one of those measures. As a developer your job is to avoid the captchas or find a way to solve them. For example, captchas could be avoided by making sure that your traffic doesn’t look like it’s been bot-generated. One way to achieve this is to minimize the amount of requests sent to a website. Another way is to simply slow down your traffic. This can be done by creating a sleep function in your code, which should make your traffic look more human-like by creating the illusion that someone is actually reading the article. You could also use a Puppeteer extension called puppeteer-extra-plugin-stealth. Another effective way to avoid captchas is to use proxy servers, which are servers that visit a website on your behalf and send over the results. By using multiple proxy servers, traffic can be rerouted to numerous locations, therefore making the website think that it is being visited by different people. However, what should you do if you are ultimately still presented with a captcha? One approach you could use is to pay for a service that would solve captchas for your bot, or you could send them to yourself and solve it directly.
- Another essential aspect of web scraping is actually refining that data so that it can actually be used. This is referred to as data mining because you have to extract the actual valuable bits of data (often in the form of numbers) from paragraphs. For humans this is very simple, however this can be a challenge for machines.
Now that we have gone over the hurdles of web scraping let’s discover how to actually build a basic web scraper. Puppeteer is a package in JavaScript that allows you to use the browser programmatically (or not) meaning being able to use all the functionalities of the browser without actually using it. It is a way to manage the browser virtually with code allowing you to perform automation, such as being able to screenshot websites.
The main advantage of this API is that it’s VERY easy to use, using JavaScript’s async language features, as there is no need for complex callback nesting. For example, let’s demonstrate a simple way to screenshot some Roblox groups.
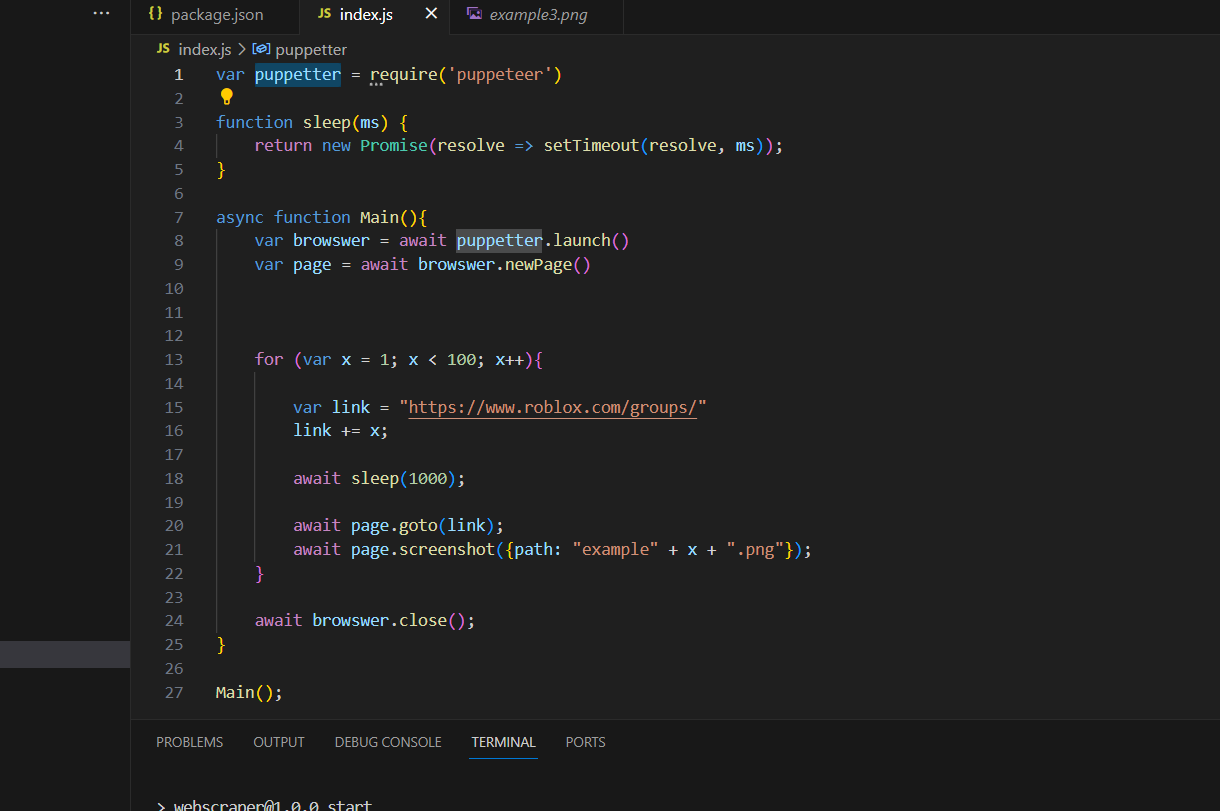
As you can see, the code is relatively straightforward. The code simulates the semantics for how real browsers work; for example, browser.newPage() opens a new tab. In this new tab, one thing we can do is open links, in this example, the program opens 100 links in the tab as it goes through various Roblox groups. The command page.goto(link) goes to the link, and page.screenshot() allows programmers to specify a path on their computer where the image of what the virtual browser sees when the tab is open can be stored.
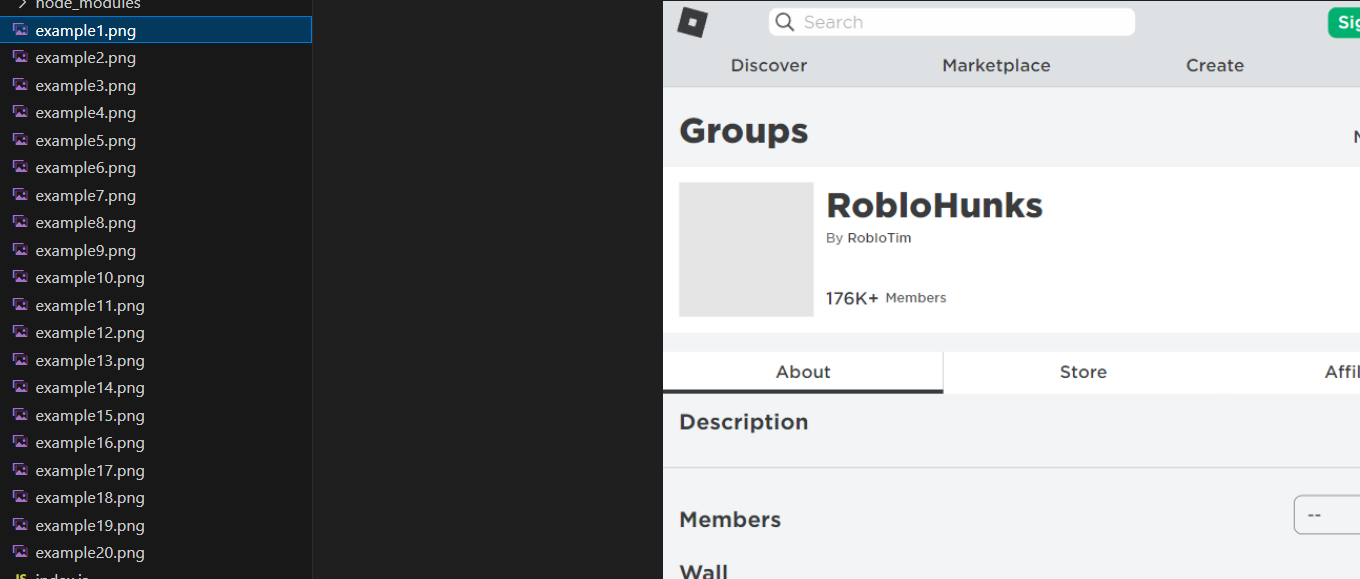
Here is the result: What are all the await calls doing? Puppeteer’s operations are non blocking, meaning they start running in the background: essentially, this means that when you call browser.newpage() it starts running in the background. While this could be useful, we want to open our link ONCE it finishes. If we directly call browser.openlink(0) without the await, it might open the page without the browser loading.
That is why await is used, although this code is pretty inefficient as it waits for each website to be loaded and screenshotting instead of doing it in the background for each website.
Puppeteer also allows you to select any HTML element on the page, such as divs, links, etc. This can be useful when you need to extract data from specific HTML elements.